Virtual Time is a subject I studied in my early days right out of college. It’s a concept we explored while thinking about the biggest problem computer processing would eventually experience: the speed of the electron. No matter how short the distance you make between two elements that process data, you will find the bottleneck to be the Physics of the electron. The only way we could conceive of surpassing this was parallel processing: having two or more processors working on the execution of code at the same time. Parallel processing has been discussed for years, as we all know, so this wasn’t anything new that we were conjuring up. But its biggest Achilles’ heel was data integrity: how do you keep the data accurate and current while processing instructions of a program in parallel with one another?
That’s when we heard of a radically new concept: Virtual Time. The idea followed the lines of predictive analysis, but also didn’t care what the outcome of any particular computation was, since the instruction realistically was being executed “in the future” of any given data stream.
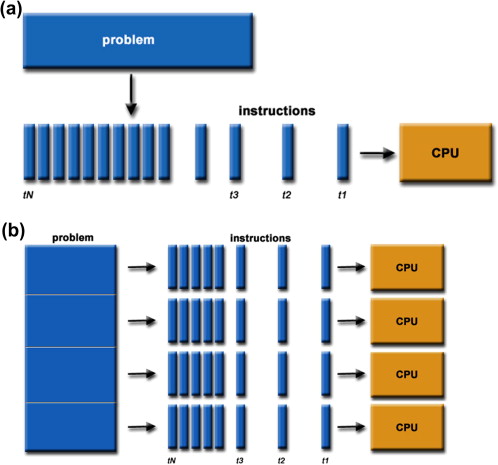
To apply the concept practically, let’s consider the following example: A piece of code has ten instructions. If we imagine the instructions as a stack in a Pez dispenser, we can anticipate that a single processor will take ten cycles to process the instructions in the code, removing each from the stack, one instruction at a time. Now, let’s lay that Pez dispenser down on its side, and line up ten processors next to it, one for each instruction. Those ten processors will execute the ten instructions in one cycle.
If the computations were correct, you effectively leapt forward in time, possibly by nine cycles, thus defying the limitations Physics had put upon you! If you were wrong, well then you had to go back “in time” to the point of failure and process the data again with the correct information. But this model gave you a potential time delta of nine cycles in this experiment. So, even if you had to back up to instruction six, you still were six cycles ahead in the future, since the first six instructions weren’t impacted by the process outcome!
Of course, the example we’re talking about is an over-simplified one. Nonetheless, there should exist process opportunities where this model adds significant value. The goal is to accumulate enough forward leaps such that the fall-backs do not detract from your overall delta in cycle positions ahead in Virtual Time. In other words, you should always come out ahead, compared to processing data in a traditional sense.
I haven’t revisited this concept in quite some time, so I can’t say where it stands in today’s realm of parallel processing. I know that folks are now looking to Quantum Computing to take us to that next step, and it certainly looks exciting enough to pursue. But we may yet find that some of the early concepts we pursued then may come back to help us out in time, perhaps in “Virtual Time”.
Interesting articles:
Some interesting reading that go more in depth about Virtual Time: